


HHIDE_DUMP
Гость
H
HHIDE_DUMP
Гость
Конечно же все вы когда-нибудь пользовались прокси, и сегодня мы научимся делать парсер для добычи оных.

Прокси-сервер — промежуточный сервер, позволяющий замаскировать собственное местоположение.
Парсер - это программа, которая автоматизирует сбор информации с заданных ресурсов.
Приступим:
Для начала мы накидаем такую конструкцию
Модуль requests нужен для обращения к серверу, BeautifulSoup анализирует html код, и последняя запись это точка входа в главную функцию main() которую мы напишем в самом конце программы.
Далее создадим функцию get_html которая принимает аргумент site. Переменная r обращается к requests методом get и получает чтение site. Функция возвращает r выведенную в текст.
Далее создаём вторую функцию get_page_data для получения данных со страницы html. Эти сырые данные попадают в переменную soup. Обрабатывает данные BeautifulSoup, принимая код html. И в качестве парсера указываем 'lxml.
Добывать прокси мы будем с
В исходнике мы видим что proxy заключены в таблицу, и у этой таблицы есть id 'theProxyList'
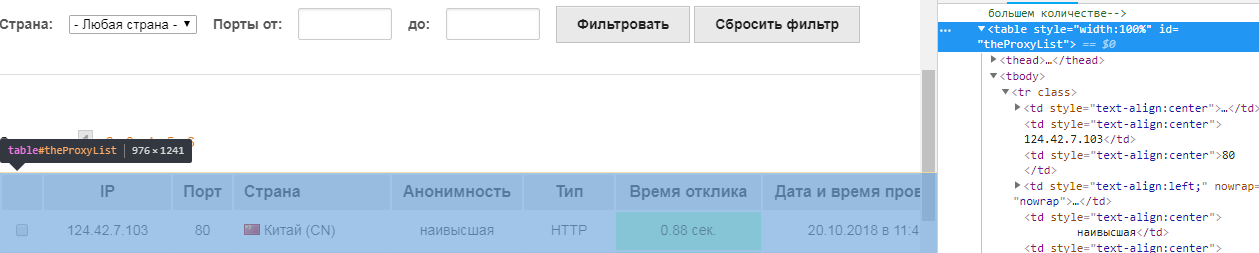
Внутри таблицы находится тег tbody

А внутри тега tbody есть теги tr при наведении на которые выделяется строка (линия) с нужными данными.

Значит чтобы спарсить эту линию добавим в нашу функцию такую строку
Прекрасно, начало есть. Но это ещё не всё друзья, не так быстро дела делаются.
В функцию get_page_data теперь добавим цикл, в котором мы будем обращаться по индексу к нужным данным. Дата и время проверки не будем парсить, так как это не такая нужная информация. Остальное преобразуем в текст с помощью text
Теперь полученные данные запишем в словарь
И выведем на печать print(data).
Осталось написать главную функцию, в ней мы принимаем url сайта, и по цепочке идёт обработка предыдущими функциями.
Наконец-то запускаем скрипт и видим следующую картину:

Данные успешно спарсились, но картинка не такая как хотелось бы. Присутствует куча мусора в виде \xa0, \r\n, \r\n\t\t\t\t\t
Значит будем от него избавляться. С помощью replace удалим всё лишнее, и для этого поправим наш цикл
Запускаем по новой - другое дело, уже всё читабельно.

Исходник:
Ну вот мы и научились некоторым приёмам парсинга страниц. В следующей статье мы продолжим работать с этим парсером и добавим функционал.
До встречи!")
Прокси-сервер — промежуточный сервер, позволяющий замаскировать собственное местоположение.
Парсер - это программа, которая автоматизирует сбор информации с заданных ресурсов.
Приступим:
Для начала мы накидаем такую конструкцию
Код:
import requests
from bs4 import BeautifulSoup
if __name__ == '__main__':
main()Далее создадим функцию get_html которая принимает аргумент site. Переменная r обращается к requests методом get и получает чтение site. Функция возвращает r выведенную в текст.
Код:
def get_html(site):
r = requests.get(site)
return r.text
Код:
def get_page_data(html):
soup = BeautifulSoup(html, 'lxml')Пожалуйста,
Вход
или
Регистрация
для просмотра содержимого URL-адресов!
поэтому заходим по этому адресу, открываем инструменты разработчика кнопкой F12. Удобнее всего, на мой взгляд реализовано в ГуглХром. Кому-то нравится в лисе, но это не так важно. Наша задача определить в исходном коде, где находятся нужные нам строки.В исходнике мы видим что proxy заключены в таблицу, и у этой таблицы есть id 'theProxyList'
Внутри таблицы находится тег tbody
А внутри тега tbody есть теги tr при наведении на которые выделяется строка (линия) с нужными данными.
Значит чтобы спарсить эту линию добавим в нашу функцию такую строку
Код:
line = soup.find('table', id='theProxyList').find('tbody').find_all('tr')
# Ищем с помощью find 'tbody' и с помощью find_all все 'tr'В функцию get_page_data теперь добавим цикл, в котором мы будем обращаться по индексу к нужным данным. Дата и время проверки не будем парсить, так как это не такая нужная информация. Остальное преобразуем в текст с помощью text
Код:
for tr in line:
td = tr.find_all('td')
ip = td[1].text
port = td[2].text
country = td[3].text
anonym = td[4].text
types = td[5].text
time = td[6].text
Код:
data = {'ip': ip,
'Порт': port,
'Страна': country,
'Анонимность': anonym,
'Тип': types,
'Время отклика': time}Осталось написать главную функцию, в ней мы принимаем url сайта, и по цепочке идёт обработка предыдущими функциями.
Код:
def main():
url = 'http://foxtools.ru/Proxy'
get_page_data(get_html(url))Данные успешно спарсились, но картинка не такая как хотелось бы. Присутствует куча мусора в виде \xa0, \r\n, \r\n\t\t\t\t\t
Значит будем от него избавляться. С помощью replace удалим всё лишнее, и для этого поправим наш цикл
Код:
for tr in line:
td = tr.find_all('td')
ip = td[1].text
port = td[2].text
country = td[3].text.replace('\xa0', '')
anonym = td[4].text.replace('\r\n ', '')
types = td[5].text.replace('\r\n\t\t\t\t\t', '').replace('\r\n ', '')
time = td[6].textИсходник:
Код:
import requests
from bs4 import BeautifulSoup
def get_html(site):
r = requests.get(site)
return r.text
def get_page_data(html):
soup = BeautifulSoup(html, 'lxml')
line = soup.find('table', id='theProxyList').find('tbody').find_all('tr')
for tr in line:
td = tr.find_all('td')
ip = td[1].text
port = td[2].text
country = td[3].text.replace('\xa0', '')
anonym = td[4].text.replace('\r\n ', '')
types = td[5].text.replace('\r\n\t\t\t\t\t', '').replace('\r\n ', '')
time = td[6].text
data = {'ip': ip,
'Порт': port,
'Страна': country,
'Анонимность': anonym,
'Тип': types,
'Время отклика': time}
print(data)
def main():
url = 'http://foxtools.ru/Proxy'
get_page_data(get_html(url))
if __name__ == '__main__':
main()До встречи!