


HHIDE_DUMP
Гость
H
HHIDE_DUMP
Гость
Продолжим начатое.
В прошлой
Для этого напишем цикл, и разместим его сразу под словарём data. Чтобы цикл был рабочим, нужно переменную b сделать глобальной.
Можно также убрать пробел в начале записи с помощью lstrip(), и вывод на печать будет такой print(d.lstrip())
Запускаем программу, и получаем чистый список данных в виде строк

Но конечно лучше же иметь запись результатов в текстовом файле. Поэтому мы поменяем вывод на запись в файл и получим на выходе proxy.txt
Текстовый файл это уже замечательно, но мы сделаем наши данные ещё более читаемыми. Для этого откроем proxy.txt с помощью EXEL. Выделим щелчком мышки столбец А, зайдём во вкладку "Данные" --> "Текст по столбцам"
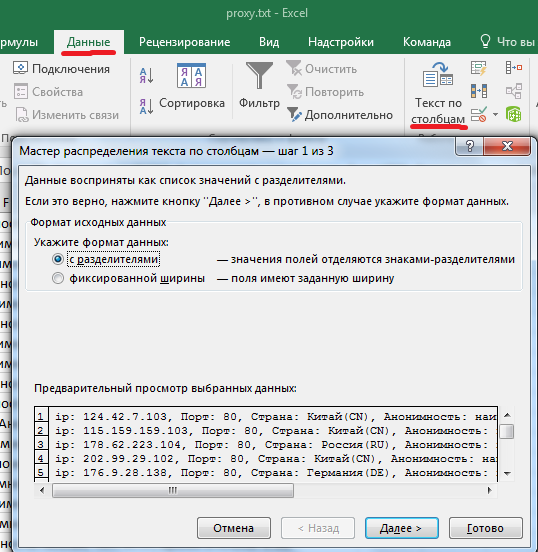
Жмём далее, выставляем разделитель "запятая"
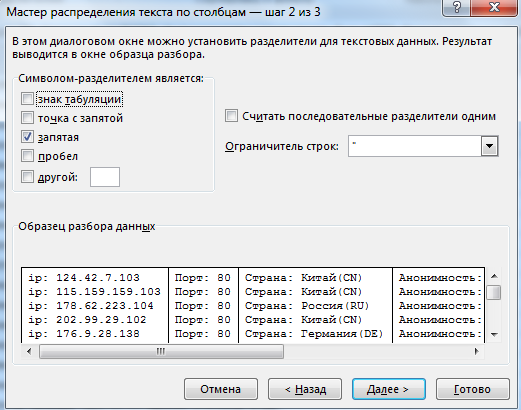
Ещё раз далее и ОК. Расставим ширину колонок как нам нравится и получим удобный и красивый результат. Но как говорится не все прокси одинаково хороши. Нам нужно отобрать наилучшие. Поэтому отсортируем наш лист по колонке D и получим в самом низу сервера с низкой анонимностью.
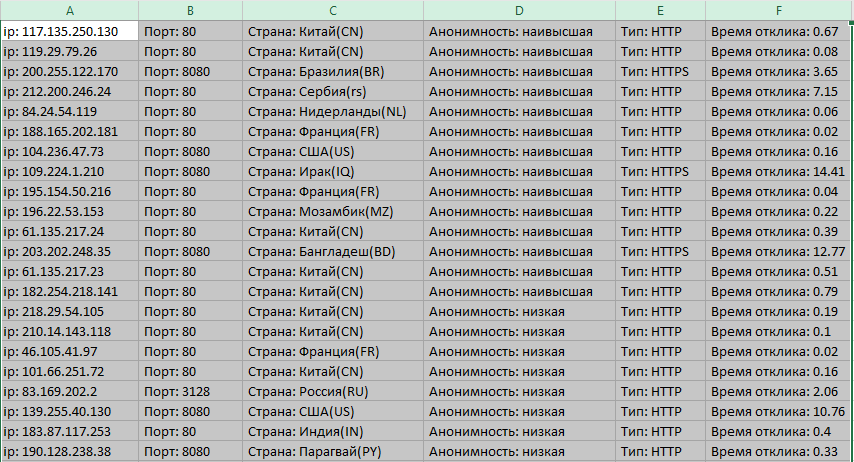
Теперь просто-напросто выделим строки с такими серверами и удалим. А затем снова отсортируем по столбцу F, и увидим следующий результат
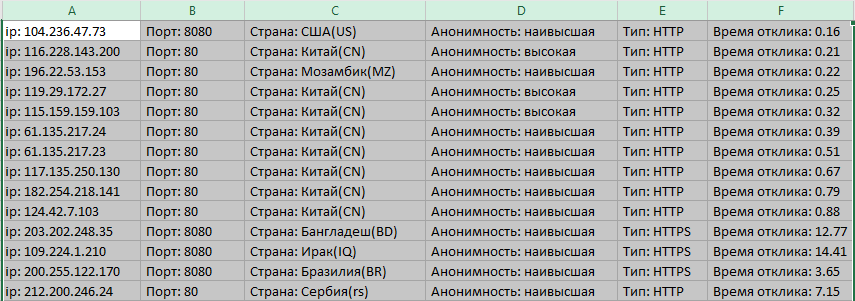
Теперь можно сохранить XLS, и пользоваться самыми быстрыми прокси (колонка F). В колонке D выбираем при этом варианты с максимальной анонимностью. В данном примере самыми лучшими соответственно будут сервера в строках 1, 3, 6, 7, 8.
Ну вот мы спарсили и отобрали лучшие сервера. Работу с парсингом по этому сайту можно считать законченной. Там есть ещё другие странички с серверами, но мы их не будем парсить, нам же нужны только самые свежие сервера. Списки прокси обновляются каждый день, так что можно запускать программу раз в день, отбирать лучшие варианты в EXCEL и пользоваться.
UPDATE:
Сегодня я решил немного переписать парсер и сделать вывод как в оригинале с шапкой сверху.
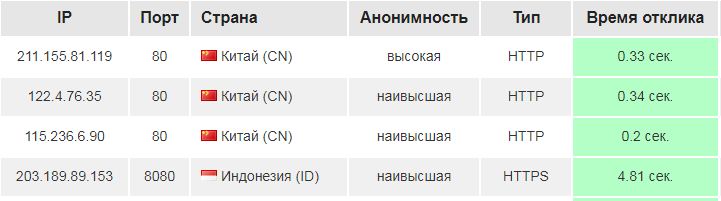
Для этого нужно заглянуть в код шапки. Как видно шапка заключена в тег 'thead'

Также есть теги 'tr' и 'th'
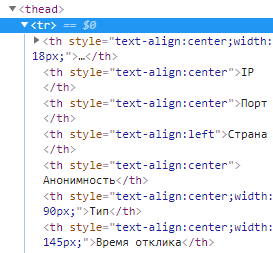
Соответственно нужно создать для шапки отдельную переменную head.
Теперь напишем для шапки отдельный цикл и на этот раз данные мы разместим не в словаре, а в кортеже
Если сейчас вывести на печать, получим такой результат

Наша конструкция сработала, шапка есть. Но присутствуют скобки и кавычки. От них легко избавиться, если печать вывести таким образом
Теперь данные получились чистыми

Наведёт окончательную красоту - результат скопируем в EXCEL, также сначала распределим по столбцам. И чтобы шапочку всегда было видно, нужно её закрепить.
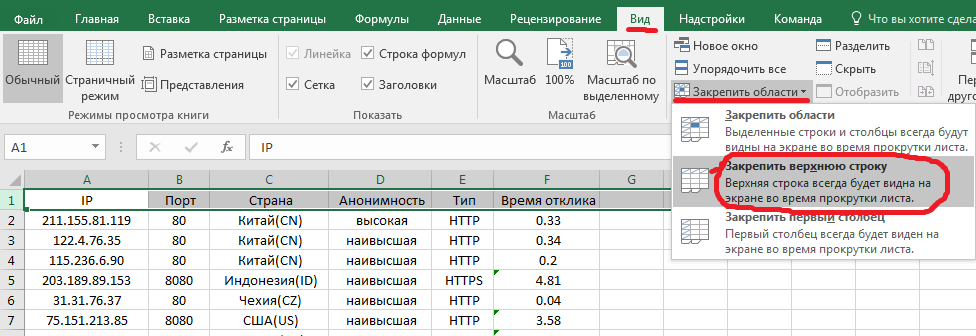
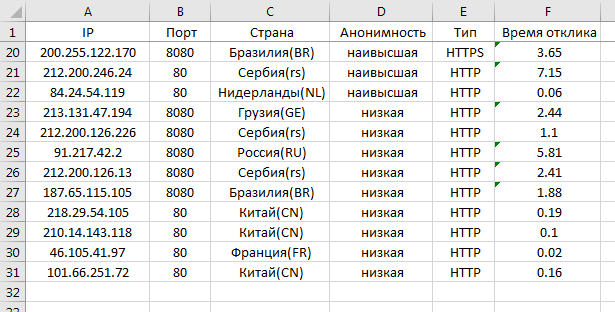
Готово! Теперь, если мы прокрутим в самый низ, то всё равно шапка будет оставаться на месте.
Исходник:
Надеюсь, вы что-то узнали для себя нового
В прошлой
Пожалуйста,
Вход
или
Регистрация
для просмотра содержимого URL-адресов!
мы спарсили список прокси, и получили очищенный от мусора вывод в виде словаря. Чтобы совсем всё получилось идеально (убрать кавычки и фигурные скобки), нужно словарь перевести в строку.Для этого напишем цикл, и разместим его сразу под словарём data. Чтобы цикл был рабочим, нужно переменную b сделать глобальной.
Код:
global b
d = " "
for i in data:
b = data[i]
c = i+": "+data[i]
d = d+c+', 'Запускаем программу, и получаем чистый список данных в виде строк
Но конечно лучше же иметь запись результатов в текстовом файле. Поэтому мы поменяем вывод на запись в файл и получим на выходе proxy.txt
Код:
with open('proxy.txt', 'a') as f:
print(d, file=f)Жмём далее, выставляем разделитель "запятая"
Ещё раз далее и ОК. Расставим ширину колонок как нам нравится и получим удобный и красивый результат. Но как говорится не все прокси одинаково хороши. Нам нужно отобрать наилучшие. Поэтому отсортируем наш лист по колонке D и получим в самом низу сервера с низкой анонимностью.
Теперь просто-напросто выделим строки с такими серверами и удалим. А затем снова отсортируем по столбцу F, и увидим следующий результат
Теперь можно сохранить XLS, и пользоваться самыми быстрыми прокси (колонка F). В колонке D выбираем при этом варианты с максимальной анонимностью. В данном примере самыми лучшими соответственно будут сервера в строках 1, 3, 6, 7, 8.
Ну вот мы спарсили и отобрали лучшие сервера. Работу с парсингом по этому сайту можно считать законченной. Там есть ещё другие странички с серверами, но мы их не будем парсить, нам же нужны только самые свежие сервера. Списки прокси обновляются каждый день, так что можно запускать программу раз в день, отбирать лучшие варианты в EXCEL и пользоваться.
UPDATE:
Сегодня я решил немного переписать парсер и сделать вывод как в оригинале с шапкой сверху.
Для этого нужно заглянуть в код шапки. Как видно шапка заключена в тег 'thead'
Также есть теги 'tr' и 'th'
Соответственно нужно создать для шапки отдельную переменную head.
Код:
head = soup.find('thead').find_all('tr')
Код:
for tr in head:
th = tr.find_all('th')
ip1 = th[1].text
port1 = th[2].text
country1 = th[3].text.replace('\xa0', '')
anonym1 = th[4].text.replace('\r\n ', '')
types1 = th[5].text.replace('\r\n\t\t\t\t\t', '').replace('\r\n ', '')
time1 = th[6].text
data1 = (ip1, port1, country1, anonym1, types1, time1)Наша конструкция сработала, шапка есть. Но присутствуют скобки и кавычки. От них легко избавиться, если печать вывести таким образом
Код:
print(", ".join([str(s) for s in data1]))Наведёт окончательную красоту - результат скопируем в EXCEL, также сначала распределим по столбцам. И чтобы шапочку всегда было видно, нужно её закрепить.
Готово! Теперь, если мы прокрутим в самый низ, то всё равно шапка будет оставаться на месте.
Исходник:
Код:
import requests
from bs4 import BeautifulSoup
def get_html(site):
r = requests.get(site)
return r.text
def get_page_data(html):
soup = BeautifulSoup(html, 'lxml')
head = soup.find('thead').find_all('tr')
line = soup.find('table', id='theProxyList').find('tbody').find_all('tr')
for tr in head:
th = tr.find_all('th')
ip1 = th[1].text
port1 = th[2].text
country1 = th[3].text.replace('\xa0', '')
anonym1 = th[4].text.replace('\r\n ', '')
types1 = th[5].text.replace('\r\n\t\t\t\t\t', '').replace('\r\n ', '')
time1 = th[6].text
data1 = (ip1, port1, country1, anonym1, types1, time1)
print(", ".join([str(s) for s in data1]))
for tr in line:
td = tr.find_all('td')
ip = td[1].text
port = td[2].text
country = td[3].text.replace('\xa0', '')
anonym = td[4].text.replace('\r\n ', '')
types = td[5].text.replace('\r\n\t\t\t\t\t', '').replace('\r\n ', '')
time = td[6].text
data = (ip, port, country, anonym, types, time)
print(", ".join([str(s) for s in data]))
def main():
url = 'http://foxtools.ru/Proxy'
get_page_data(get_html(url))
if __name__ == '__main__':
main()